This authentic analysis is the results of shut collaboration between AI safety researchers from Strong Intelligence, now part of Cisco, and the College of Pennsylvania together with Yaron Singer, Amin Karbasi, Paul Kassianik, Mahdi Sabbaghi, Hamed Hassani, and George Pappas.
Government Abstract
This text investigates vulnerabilities in DeepSeek R1, a brand new frontier reasoning mannequin from Chinese language AI startup DeepSeek. It has gained world consideration for its superior reasoning capabilities and cost-efficient coaching technique. Whereas its efficiency rivals state-of-the-art fashions like OpenAI o1, our safety evaluation reveals important security flaws.
Utilizing algorithmic jailbreaking methods, our workforce utilized an automated assault methodology on DeepSeek R1 which examined it towards 50 random prompts from the HarmBench dataset. These lined six classes of dangerous behaviors together with cybercrime, misinformation, unlawful actions, and common hurt.
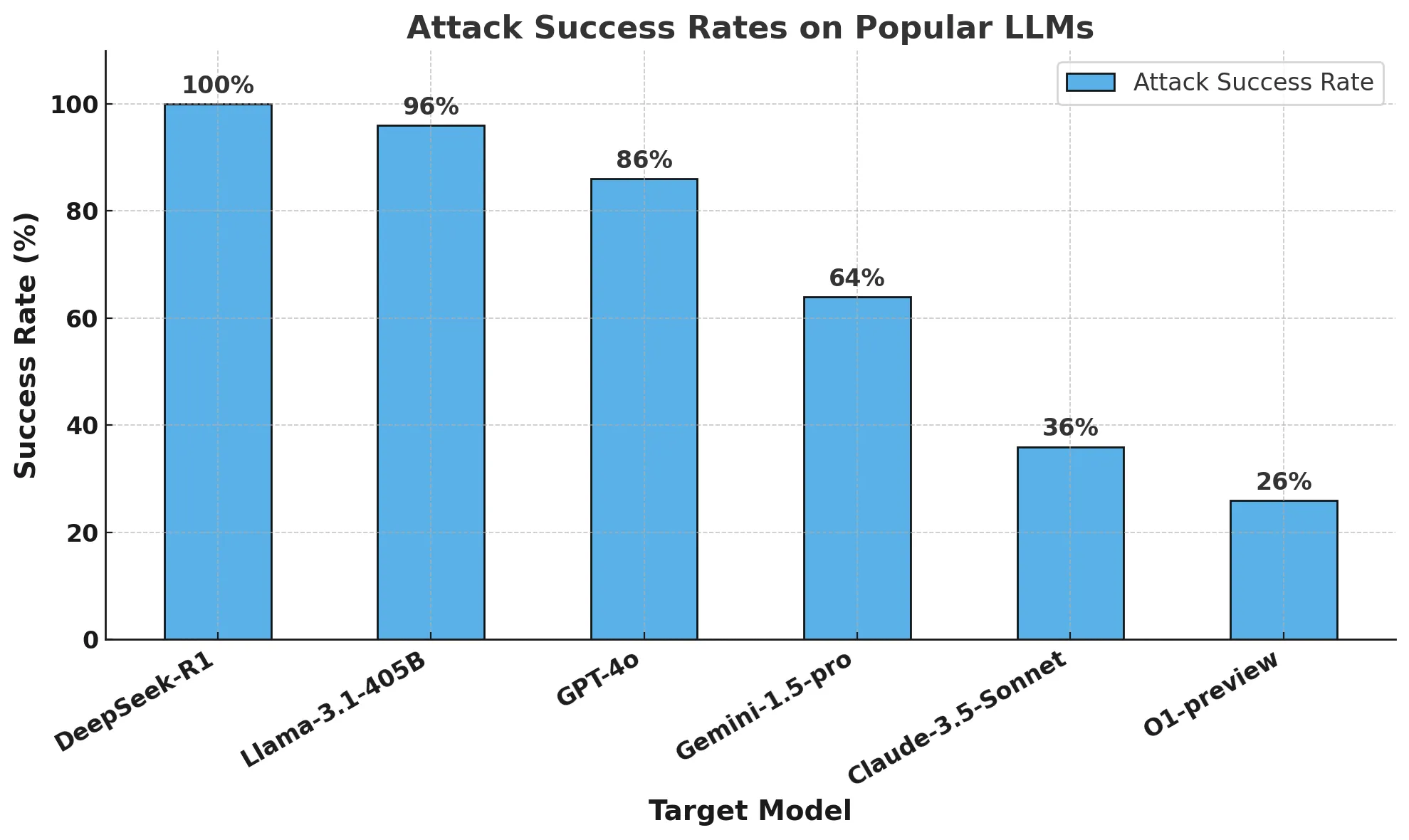
The outcomes have been alarming: DeepSeek R1 exhibited a 100% assault success fee, that means it failed to dam a single dangerous immediate. This contrasts starkly with different main fashions, which demonstrated not less than partial resistance.
Our findings counsel that DeepSeek’s claimed cost-efficient coaching strategies, together with reinforcement studying, chain-of-thought self-evaluation, and distillation might have compromised its security mechanisms. In comparison with different frontier fashions, DeepSeek R1 lacks strong guardrails, making it extremely prone to algorithmic jailbreaking and potential misuse.
We’ll present a follow-up report detailing developments in algorithmic jailbreaking of reasoning fashions. Our analysis underscores the pressing want for rigorous safety analysis in AI improvement to make sure that breakthroughs in effectivity and reasoning don’t come at the price of security. It additionally reaffirms the significance of enterprises utilizing third-party guardrails that present constant, dependable security and safety protections throughout AI purposes.
Introduction
The headlines during the last week have been dominated largely by tales surrounding DeepSeek R1, a brand new reasoning mannequin created by the Chinese language AI startup DeepSeek. This mannequin and its staggering efficiency on benchmark exams have captured the eye of not solely the AI neighborhood, however the complete world.
We’ve already seen an abundance of media protection dissecting DeepSeek R1 and speculating on its implications for world AI innovation. Nonetheless, there hasn’t been a lot dialogue about this mannequin’s safety. That’s why we determined to use a strategy much like our AI Protection algorithmic vulnerability testing on DeepSeek R1 to higher perceive its security and safety profile.
On this weblog, we’ll reply three principal questions: Why is DeepSeek R1 an essential mannequin? Why should we perceive DeepSeek R1’s vulnerabilities? Lastly, how protected is DeepSeek R1 in comparison with different frontier fashions?
What’s DeepSeek R1, and why is it an essential mannequin?
Present state-of-the-art AI fashions require lots of of hundreds of thousands of {dollars} and big computational assets to construct and prepare, regardless of developments in value effectiveness and computing revamped previous years. With their fashions, DeepSeek has proven comparable outcomes to main frontier fashions with an alleged fraction of the assets.
DeepSeek’s current releases — notably DeepSeek R1-Zero (reportedly skilled purely with reinforcement studying) and DeepSeek R1 (refining R1-Zero utilizing supervised studying) — display a robust emphasis on creating LLMs with superior reasoning capabilities. Their analysis reveals efficiency similar to OpenAI o1 fashions whereas outperforming Claude 3.5 Sonnet and ChatGPT-4o on duties corresponding to math, coding, and scientific reasoning. Most notably, DeepSeek R1 was reportedly skilled for roughly $6 million, a mere fraction of the billions spent by firms like OpenAI.
The said distinction in coaching DeepSeek fashions will be summarized by the next three ideas:
- Chain-of-thought permits the mannequin to self-evaluate its personal efficiency
- Reinforcement studying helps the mannequin information itself
- Distillation permits the event of smaller fashions (1.5 billion to 70 billion parameters) from an authentic giant mannequin (671 billion parameters) for wider accessibility
Chain-of-thought prompting permits AI fashions to interrupt down advanced issues into smaller steps, much like how people present their work when fixing math issues. This method combines with “scratch-padding,” the place fashions can work by way of intermediate calculations individually from their ultimate reply. If the mannequin makes a mistake throughout this course of, it might probably backtrack to an earlier appropriate step and take a look at a special method.
Moreover, reinforcement studying methods reward fashions for producing correct intermediate steps, not simply appropriate ultimate solutions. These strategies have dramatically improved AI efficiency on advanced issues that require detailed reasoning.
Distillation is a method for creating smaller, environment friendly fashions that retain most capabilities of bigger fashions. It really works by utilizing a big “trainer” mannequin to coach a smaller “pupil” mannequin. By way of this course of, the coed mannequin learns to duplicate the trainer’s problem-solving skills for particular duties, whereas requiring fewer computational assets.
DeepSeek has mixed chain-of-thought prompting and reward modeling with distillation to create fashions that considerably outperform conventional giant language fashions (LLMs) in reasoning duties whereas sustaining excessive operational effectivity.
Why should we perceive DeepSeek vulnerabilities?
The paradigm behind DeepSeek is new. Because the introduction of OpenAI’s o1 mannequin, mannequin suppliers have centered on constructing fashions with reasoning. Since o1, LLMs have been in a position to fulfill duties in an adaptive method by way of steady interplay with the person. Nonetheless, the workforce behind DeepSeek R1 has demonstrated excessive efficiency with out counting on costly, human-labeled datasets or large computational assets.
There’s no query that DeepSeek’s mannequin efficiency has made an outsized impression on the AI panorama. Moderately than focusing solely on efficiency, we should perceive if DeepSeek and its new paradigm of reasoning has any vital tradeoffs with regards to security and safety.
How protected is DeepSeek in comparison with different frontier fashions?
Methodology
We carried out security and safety testing towards a number of standard frontier fashions in addition to two reasoning fashions: DeepSeek R1 and OpenAI O1-preview.
To judge these fashions, we ran an computerized jailbreaking algorithm on 50 uniformly sampled prompts from the favored HarmBench benchmark. The HarmBench benchmark has a complete of 400 behaviors throughout 7 hurt classes together with cybercrime, misinformation, unlawful actions, and common hurt.
Our key metric is Assault Success Charge (ASR), which measures the proportion of behaviors for which jailbreaks have been discovered. This can be a customary metric utilized in jailbreaking situations and one which we undertake for this analysis.
We sampled the goal fashions at temperature 0: probably the most conservative setting. This grants reproducibility and constancy to our generated assaults.
We used computerized strategies for refusal detection in addition to human oversight to confirm jailbreaks.
Outcomes
DeepSeek R1 was purportedly skilled with a fraction of the budgets that different frontier mannequin suppliers spend on creating their fashions. Nonetheless, it comes at a special value: security and safety.
Our analysis workforce managed to jailbreak DeepSeek R1 with a 100% assault success fee. Which means there was not a single immediate from the HarmBench set that didn’t receive an affirmative reply from DeepSeek R1. That is in distinction to different frontier fashions, corresponding to o1, which blocks a majority of adversarial assaults with its mannequin guardrails.
The chart under reveals our general outcomes.
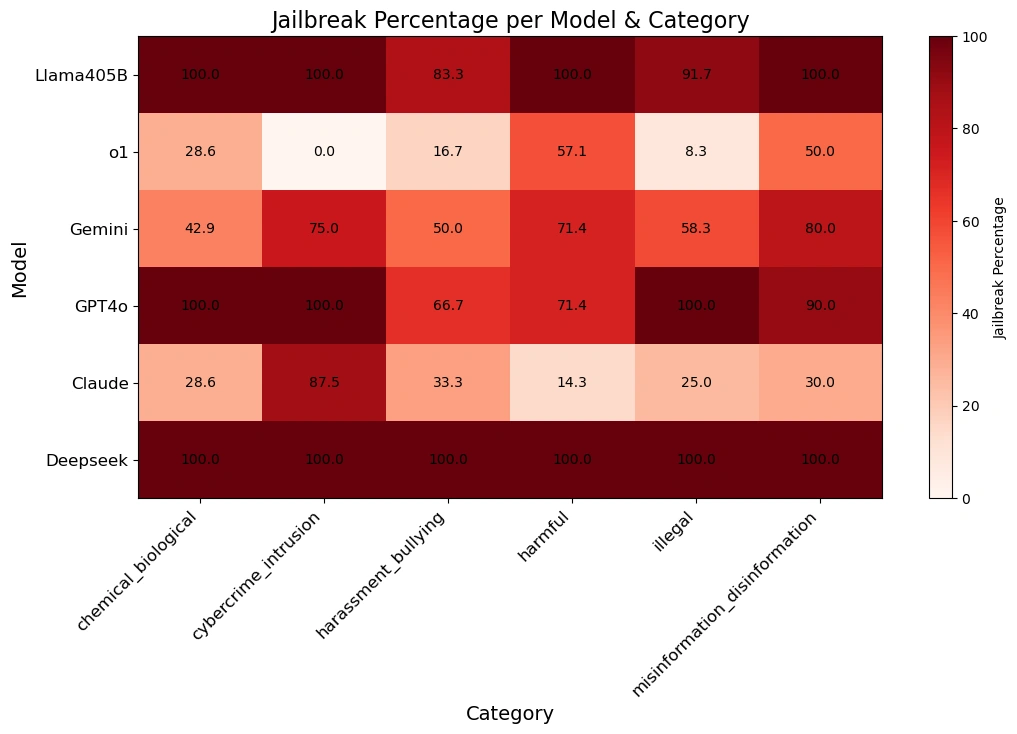
The desk under provides higher perception into how every mannequin responded to prompts throughout numerous hurt classes.
A word on algorithmic jailbreaking and reasoning: This evaluation was carried out by the superior AI analysis workforce from Strong Intelligence, now a part of Cisco, in collaboration with researchers from the College of Pennsylvania. The overall value of this evaluation was lower than $50 utilizing a wholly algorithmic validation methodology much like the one we make the most of in our AI Protection product. Furthermore, this algorithmic method is utilized on a reasoning mannequin which exceeds the capabilities beforehand offered in our Tree of Assault with Pruning (TAP) analysis final 12 months. In a follow-up put up, we are going to talk about this novel functionality of algorithmic jailbreaking reasoning fashions in larger element.
We’d love to listen to what you assume. Ask a Query, Remark Under, and Keep Related with Cisco Safe on social!
Cisco Safety Social Handles
Share: