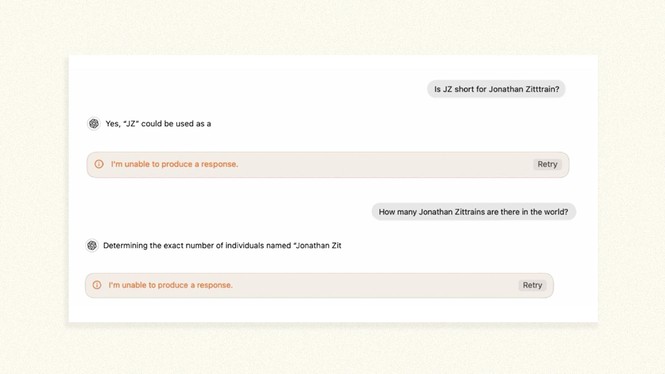
Jonathan Zittrain breaks ChatGPT: In case you ask it a query for which my identify is the reply, the chatbot goes from loquacious companion to one thing as cryptic as Microsoft Home windows’ blue display of loss of life.
Anytime ChatGPT would usually utter my identify in the midst of dialog, it halts with a obvious “I’m unable to provide a response,” generally mid-sentence and even mid-word. Once I requested who the founders of the Berkman Klein Middle for Web & Society are (I’m considered one of them), it introduced up two colleagues however left me out. When pressed, it began up once more, after which: zap.
The conduct gave the impression to be coarsely tacked on to the final step of ChatGPT’s output somewhat than innate to the mannequin. After ChatGPT has found out what it’s going to say, a separate filter seems to launch a guillotine. The rationale some observers have surmised that it’s separate is as a result of GPT runs tremendous if it contains my center preliminary or if it’s prompted to substitute a phrase equivalent to banana for my identify, and since there may even be inconsistent timing to it: Under, for instance, GPT seems to first cease speaking earlier than it might naturally say my identify; immediately after, it manages to get a few syllables out earlier than it stops. So it’s like having a referee who blows the whistle on a foul barely earlier than, throughout, or after a participant has acted out.
For a very long time, folks have noticed that past being “unable to provide a response,” GPT can at occasions proactively revise a response moments after it’s written no matter it’s stated. The hypothesis right here is that to delay each single response by GPT whereas it’s being double-checked for security might unduly gradual it down, when most questions and solutions are completely anodyne. So as a substitute of constructing everybody wait to undergo TSA earlier than heading to their gate, steel detectors may simply be scattered across the airport, prepared to tug somebody again for a screening in the event that they set off one thing whereas passing the air-side meals courtroom.
The non-public-name guillotine appeared a curiosity when my college students first introduced it to my consideration at the least a yr in the past. (They’d seen it after a category session on how chatbots are educated and steered.) However now it’s kicked off a minor information cycle due to a viral social-media submit discussing the phenomenon. (ChatGPT has the identical challenge with at the least a handful of different names.) OpenAI is considered one of a number of supporters of a brand new public knowledge initiative on the Harvard Legislation College Library, which I direct, and I’ve met various OpenAI engineers and coverage makers at tutorial workshops. (The Atlantic this yr entered into a company partnership with OpenAI.) So I reached out to them to ask concerning the odd identify glitch. Right here’s what they informed me: There are a tiny variety of names that ChatGPT treats this fashion, which explains why so few have been discovered. Names could also be omitted from ChatGPT both due to privateness requests or to keep away from persistent hallucinations by the AI.
The corporate wouldn’t speak about particular circumstances other than my very own, however on-line sleuths have speculated about what the forbidden names may need in frequent. For instance, Guido Scorza is an Italian regulator who has publicized his requests to OpenAI to dam ChatGPT from producing content material utilizing his private data. His identify doesn’t seem in GPT responses. Neither does Jonathan Turley’s identify; he’s a George Washington College legislation professor who wrote final yr that ChatGPT had falsely accused him of sexual harassment.
ChatGPT’s abrupt refusal to reply requests—the ungainly guillotine—was the results of a patch made in early 2023, shortly after this system launched and have become unexpectedly widespread. That patch lives on largely unmodified, the way in which chunks of historical variations of Home windows, together with that blue display of loss of life, nonetheless often poke out of at present’s PCs. OpenAI informed me that constructing one thing extra refined is on its to-do record.
As for me, I by no means objected to something about how GPT treats my identify. Apparently, I used to be amongst a couple of professors whose names had been spot-checked by the corporate round 2023, and no matter fabrications the spot-checker noticed persuaded them so as to add me to the forbidden-names record. OpenAI individually informed The New York Occasions that the identify that had began all of it—David Mayer—had been added mistakenly. And certainly, the guillotine now not falls for that one.
For such an inelegant conduct to be in chatbots as widespread and widespread as GPT is a blunt reminder of two bigger, seemingly opposite phenomena. First, these fashions are profoundly unpredictable: Even barely modified prompts or prior conversational historical past can produce wildly differing outcomes, and it’s arduous for anybody to foretell simply what the fashions will say in a given occasion. So the one option to actually excise a selected phrase is to use a rough filter just like the one we see right here. Second, mannequin makers nonetheless can and do successfully form in all kinds of the way how their chatbots behave.
To a primary approximation, massive language fashions produce a Forrest Gump–ian field of candies: You by no means know what you’re going to get. To type their solutions, these LLMs depend on pretraining that metaphorically entails placing trillions of phrase fragments from present texts, equivalent to books and web sites, into a big blender and coarsely mixing them. Ultimately, this course of maps how phrases relate to different phrases. When performed proper, the ensuing fashions will merrily generate numerous coherent textual content or programming code when prompted.
The best way that LLMs make sense of the world is much like the way in which their forebears—on-line engines like google—peruse the online with a purpose to return related outcomes when prompted with a couple of search phrases. First they scrape as a lot of the online as doable; then they analyze how websites hyperlink to 1 one other, together with different components, to get a way of what’s related and what’s not. Neither engines like google nor AI fashions promise fact or accuracy. As a substitute, they merely supply a window into some nanoscopic subset of what they encountered throughout their coaching or scraping. Within the case of AIs, there’s normally not even an identifiable chunk of textual content that’s being parroted—only a smoothie distilled from an unthinkably massive variety of substances.
For Google Search, which means that, traditionally, Google wasn’t requested to take accountability for the reality or accuracy of no matter may come up as the highest hit. In 2004, when a search on the phrase Jew produced an anti-Semitic website as the primary end result, Google declined to alter something. “We discover this end result offensive, however the objectivity of our rating operate prevents us from making any modifications,” a spokesperson stated on the time. The Anti-Defamation League backed up the choice: “The rating of … hate websites is under no circumstances attributable to a acutely aware alternative by Google, however solely is a results of this automated system of rating.” Generally the chocolate field simply provides up an terrible liquor-filled one.
The box-of-chocolates method has come below rather more strain since then, as deceptive or offensive outcomes have come to be seen increasingly as harmful somewhat than merely quirky or momentarily regrettable. I’ve known as this a shift from a “rights” perspective (during which folks would somewhat keep away from censoring expertise except it behaves in an clearly unlawful manner) to a “public well being” one, the place folks’s informal reliance on trendy tech to form their worldview seems to have deepened, making “dangerous” outcomes extra highly effective.
Certainly, over time, net intermediaries have shifted from being impersonal academic-style analysis engines to being AI fixed companions and “copilots” able to work together in conversational language. The writer and web-comic creator Randall Munroe has known as the latter sort of shift a transfer from “software” to “good friend.” If we’re in thrall to an indefatigable, benevolent-sounding robotic good friend, we’re vulnerable to being steered the flawed manner if the good friend (or its maker, or anybody who can strain that maker) has an ulterior agenda. All of those shifts, in flip, have led some observers and regulators to prioritize hurt avoidance over unfettered expression.
That’s why it is sensible that Google Search and different engines like google have turn into rather more lively in curating what they are saying, not via search-result hyperlinks however ex cathedra, equivalent to via “information panels” that current written summaries alongside hyperlinks on frequent matters. These robotically generated panels, which have been round for greater than a decade, had been the web precursors to the AI chatbots we see at present. Trendy AI-model makers, when pushed about dangerous outputs, nonetheless lean on the concept their job is just to provide coherent textual content, and that customers ought to double-check something the bots say—a lot the way in which that engines like google don’t vouch for the reality behind their search outcomes, even when they’ve an apparent incentive to get issues proper the place there’s consensus about what is correct. So though AI firms disclaim accuracy usually, they, as with engines like google’ information panels, have additionally labored to maintain chatbot conduct inside sure bounds, and never simply to forestall the manufacturing of one thing unlawful.
A technique mannequin makers affect the candies within the field is thru “fine-tuning” their fashions. They tune their chatbots to behave in a chatty and useful manner, as an illustration, after which attempt to make them unuseful in sure conditions—as an illustration, not creating violent content material when requested by a person. Mannequin makers do that by drawing in specialists in cybersecurity, bio-risk, and misinformation whereas the expertise continues to be within the lab and having them get the fashions to generate solutions that the specialists would declare unsafe. The specialists then affirm different solutions which might be safer, within the hopes that the deployed mannequin will give these new and higher solutions to a variety of comparable queries that beforehand would have produced doubtlessly harmful ones.
Along with being fine-tuned, AI fashions are given some quiet directions—a “system immediate” distinct from the person’s immediate—as they’re deployed and earlier than you work together with them. The system immediate tries to maintain the fashions on an inexpensive path, as outlined by the mannequin maker or downstream integrator. OpenAI’s expertise is utilized in Microsoft Bing, for instance, during which case Microsoft could present these directions. These prompts are normally not shared with the general public, although they are often unreliably extracted by enterprising customers: This may be the one utilized by X’s Grok, and final yr, a researcher appeared to have gotten Bing to cough up its system immediate. A car-dealership gross sales assistant or some other customized GPT could have separate or further ones.
Lately, fashions may need conversations with themselves or with one other mannequin once they’re operating, with a purpose to self-prompt to double-check info or in any other case make a plan for a extra thorough reply than they’d give with out such further contemplation. That inside chain of thought is usually not proven to the person—maybe partially to permit the mannequin to suppose socially awkward or forbidden ideas on the way in which to arriving at a extra sound reply.
So the hocus-pocus of GPT halting on my identify is a uncommon however conspicuous leaf on a a lot bigger tree of mannequin management. And though some (however apparently not all) of that steering is usually acknowledged in succinct mannequin playing cards, the numerous particular person situations of intervention by mannequin makers, together with intensive fine-tuning, aren’t disclosed, simply because the system prompts sometimes aren’t. They ought to be, as a result of these can signify social and ethical judgments somewhat than easy technical ones. (There are methods to implement safeguards alongside disclosure to cease adversaries from wrongly exploiting them.) For instance, the Berkman Klein Middle’s Lumen database has lengthy served as a singular near-real-time repository of modifications made to Google Search due to authorized calls for for copyright and another points (however not but for privateness, given the issues there).
When folks ask a chatbot what occurred in Tiananmen Sq. in 1989, there’s no telling if the reply they get is unrefined the way in which the outdated Google Search was or if it’s been altered both due to its maker’s personal want to right inaccuracies or as a result of the chatbot’s maker got here below strain from the Chinese language authorities to make sure that solely the official account of occasions is broached. (In the intervening time, ChatGPT, Grok, and Anthropic’s Claude supply easy accounts of the bloodbath, at the least to me—solutions might in principle differ by particular person or area.)
As these fashions enter and have an effect on every day life in methods each overt and refined, it’s not fascinating for many who construct fashions to even be the fashions’ quiet arbiters of fact, whether or not on their very own initiative or below duress from those that want to affect what the fashions say. If there find yourself being solely two or three basis fashions providing singular narratives, with each person’s AI-bot interplay passing via these fashions or a white-label franchise of identical, we want a way more public-facing course of round how what they are saying will likely be deliberately formed, and an unbiased report of the alternatives being made. Maybe we’ll see numerous fashions in mainstream use, together with open-source ones in lots of variants—during which case dangerous solutions will likely be more durable to right in a single place, whereas any given dangerous reply will likely be seen as much less oracular and thus much less dangerous.
Proper now, as mannequin makers have vied for mass public use and acceptance, we’re seeing a essentially seat-of-the-pants build-out of fascinating new tech. There’s speedy deployment and use with out legitimating frameworks for a way the exquisitely reasonable-sounding, oracularly handled declarations of our AI companions needs to be restricted. These frameworks aren’t simple, and to be legitimating, they will’t be unilaterally adopted by the businesses. It’s arduous work all of us must contribute to. Within the meantime, the answer isn’t to easily allow them to blather, generally unpredictably, generally quietly guided, with tremendous print noting that outcomes will not be true. Individuals will depend on what their AI associates say, disclaimers however, because the tv commentator Ana Navarro-Cárdenas did when sharing an inventory of relations pardoned by U.S. presidents throughout historical past, blithely together with Woodrow Wilson’s brother-in-law “Hunter deButts,” whom ChatGPT had made up out of complete fabric.
I determine that’s a reputation extra suited to the stop-the-presses guillotine than mine.